The AI SDK is a TypeScript toolkit designed to help developers build AI-powered applications using React, Next.js, Vue, Svelte, Node.js, and more.
Upstash Vector integrates with the AI SDK to provide AI applications with the benefits of vector databases, enabling applications to perform semantic search and RAG (Retrieval-Augmented Generation).
In this guide, we’ll build a RAG chatbot using the AI SDK. This chatbot will be able to both store and retrieve information from a knowledge base. We’ll use Upstash Vector as our vector database, and the OpenAI API to generate responses.
Prerequisites
Before getting started, make sure you have:
- An Upstash account (to upsert and query data)
- An OpenAI API key (to generate responses and embeddings)
Setup and Installation
We will start by bootstrapping a Next.js application with the following command:
npx create-next-app rag-chatbot --typescript
cd rag-chatbot
npm install @ai-sdk/openai ai zod @upstash/vector
.env file:
OPENAI_API_KEY=your_openai_api_key
UPSTASH_VECTOR_REST_URL=your_upstash_url
UPSTASH_VECTOR_REST_TOKEN=your_upstash_token
If you are going to use Upstash hosted embedding models, you should select one of the available options when creating your index. If you are going to use custom embedding models, you should specify the dimensions of your embedding model.
Implementation
RAG (Retrieval-Augmented Generation) is the process of enabling the model to respond with information outside of its training data by embedding a user’s query, retrieving the relevant source material (chunks) with the highest semantic similarity, and then passing them alongside the initial query as context.
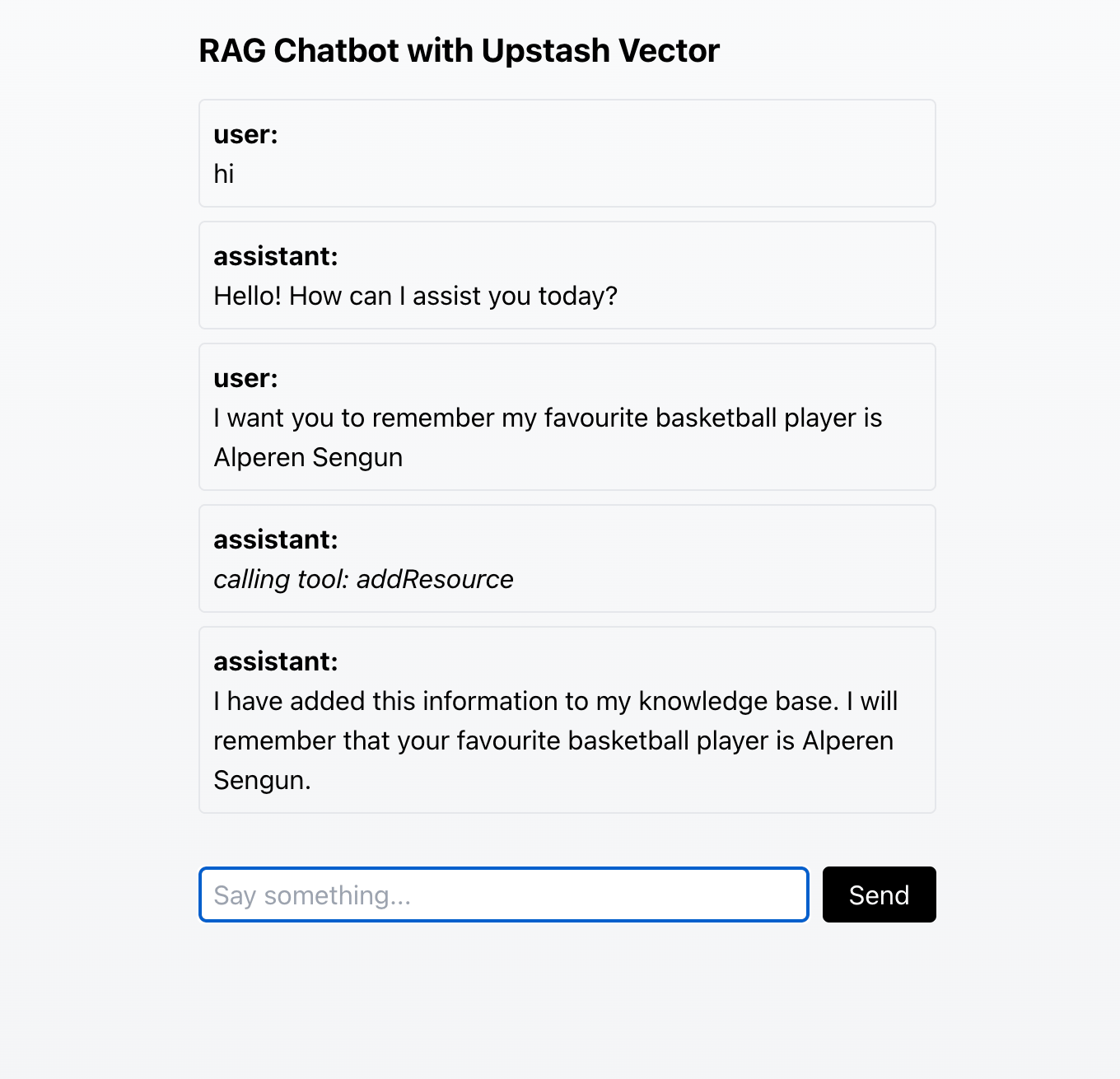
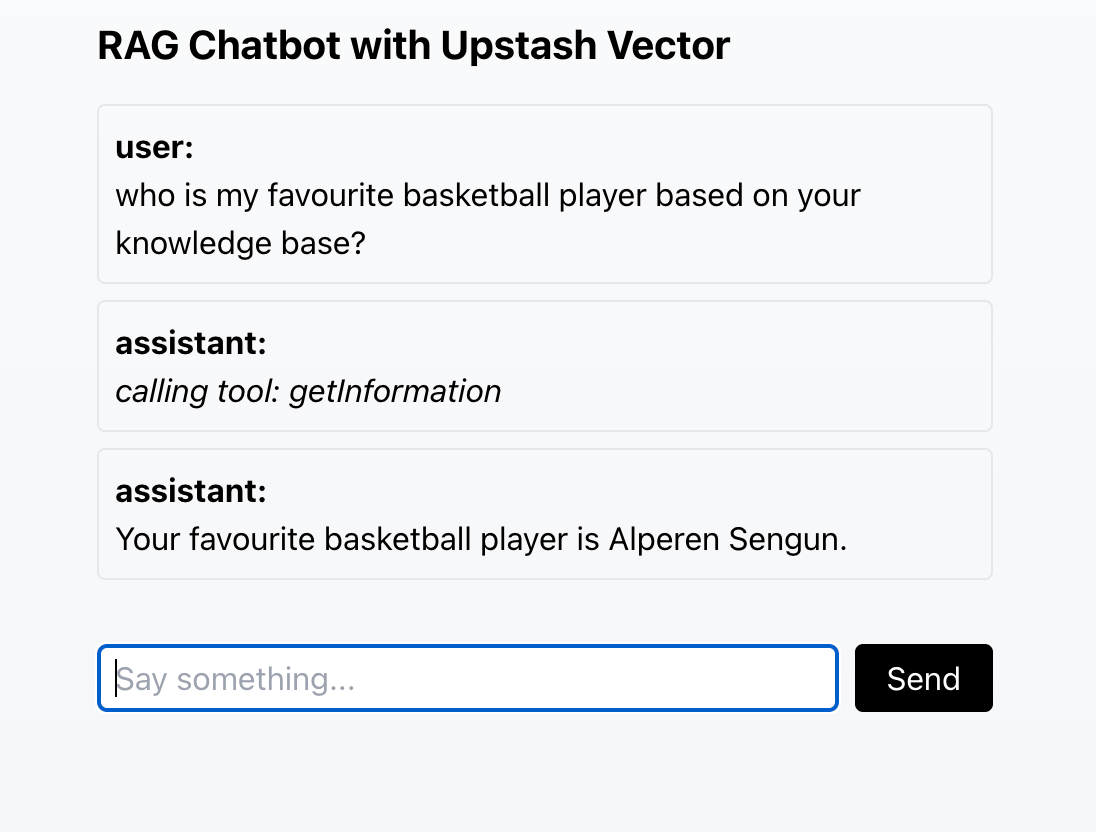
Let’s consider a simple example. Initially, a chatbot doesn’t know who your favorite basketball player is. During a conversation, I inform the chatbot that my favorite player is Alperen Sengun, and it stores this information in its knowledge base. Later, in another conversation, when I ask, “Who is my favorite basketball player?” the chatbot retrieves this information from the knowledge base and responds with “Alperen Sengun.”
Chunking + Embedding Logic
Embeddings are a way to represent the semantic meaning of words and phrases. The larger the input to your embedding, the lower the quality the embedding will be. So, how should we approach long inputs?
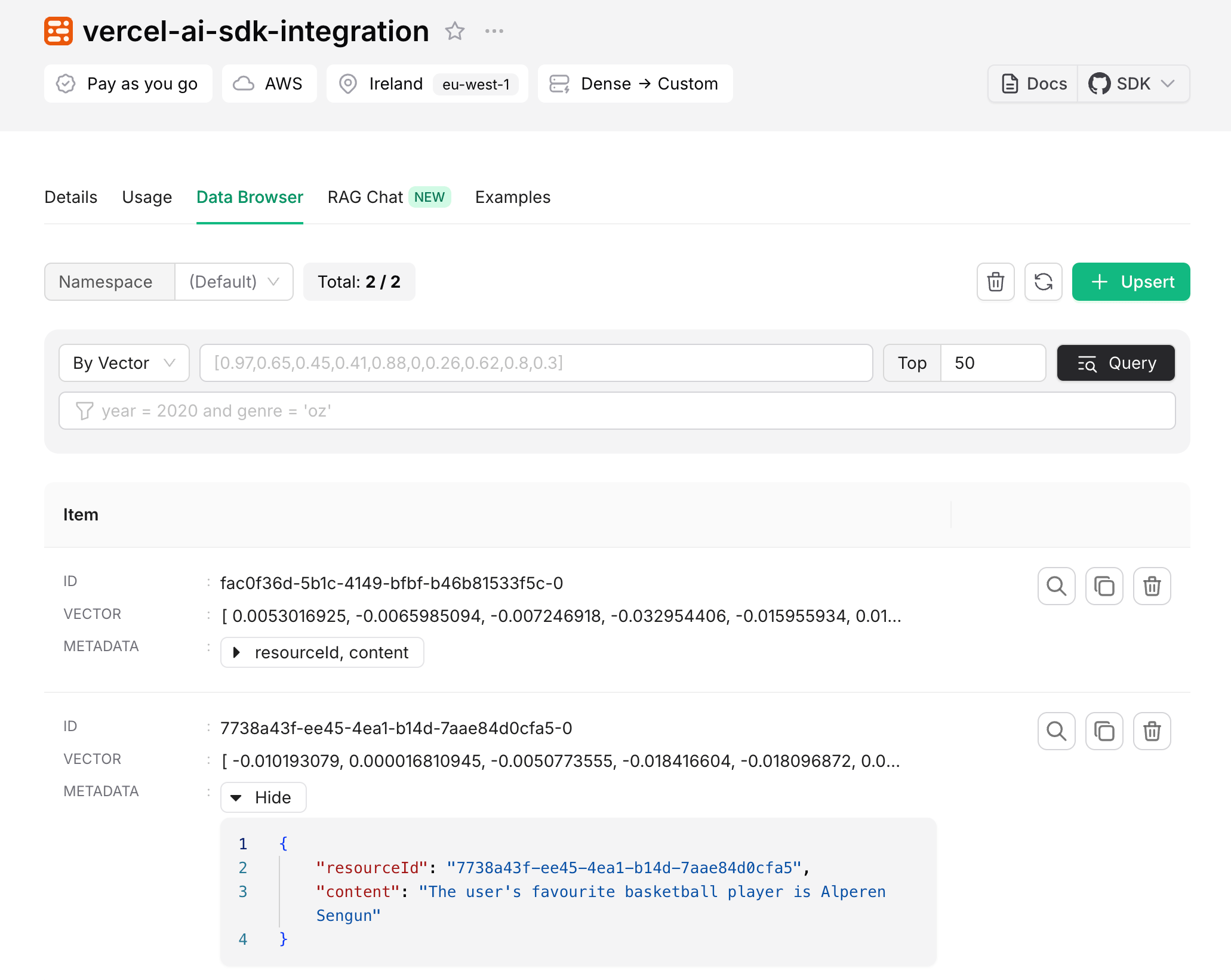
One approach would be to use chunking. Chunking refers to the process of breaking down a particular source material into smaller pieces. Once your source material is appropriately chunked, you can embed each one and then store the embedding and the chunk together in a database (Upstash Vector in our case).
Using Upstash Vector, you can upsert embeddings generated from a custom embedding model, or you can directly upsert data, and Upstash Vector will generate embeddings for you.
In this guide, we demonstrate both methods—using Upstash-hosted embedding models and using a custom embedding model (e.g., OpenAI).
Using Upstash Hosted Embedding Models
import { Index } from '@upstash/vector'
// Configure Upstash Vector client
// Make sure UPSTASH_VECTOR_REST_URL and UPSTASH_VECTOR_REST_TOKEN are in your .env
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
})
// Chunking logic: split on period
function generateChunks(input: string): string[] {
return input
.trim()
.split('.')
.filter(i => i !== '')
}
// Upsert
export async function upsertEmbedding(resourceId: string, content: string) {
const chunks = generateChunks(content)
// Convert each chunk into an Upstash upsert object
const toUpsert = chunks.map((chunk, i) => ({
id: `${resourceId}-${i}`,
data: chunk, // Using the data field instead of vector because embeddings are generated by Upstash
metadata: {
resourceId,
content: chunk, // Store the chunk as metadata to use during response generation
},
}))
await index.upsert(toUpsert)
}
// Query
export async function findRelevantContent(query: string, k = 4) {
const result = await index.query({
data: query, // Again, using the data field instead of vector field
topK: k,
includeMetadata: true, // Fetch metadata as well
})
return result
}
Using a Custom Embedding Model
Now, let’s look at how we can use a custom embedding model. We will use OpenAI’s text-embedding-ada-002 embedding model.
import { Index } from '@upstash/vector'
import { embed, embedMany } from 'ai'
import { openai } from '@ai-sdk/openai'
// Configure Upstash Vector client
const index = new Index({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
})
// Chunking logic: split on period
function generateChunks(input: string): string[] {
return input
.trim()
.split('.')
.filter(i => i !== '')
}
// Define the embedding model
const embeddingModel = openai.embedding('text-embedding-ada-002')
// Function to generate a single embedding
async function generateEmbedding(value: string): Promise<number[]> {
const input = value.replaceAll('\\n', ' ')
const { embedding } = await embed({
model: embeddingModel,
value: input,
})
return embedding
}
// Function to generate embeddings for multiple chunks
async function generateEmbeddings(
value: string,
): Promise<Array<{ content: string; embedding: number[] }>> {
const chunks = generateChunks(value)
const { embeddings } = await embedMany({
model: embeddingModel,
values: chunks,
})
return embeddings.map((vector, i) => ({
content: chunks[i],
embedding: vector,
}))
}
// Upsert
export async function upsertEmbeddings(resourceId: string, content: string) {
// Generate embeddings for each chunk
const chunkEmbeddings = await generateEmbeddings(content)
// Convert each chunk into an Upstash upsert object
const toUpsert = chunkEmbeddings.map((chunk, i) => ({
id: `${resourceId}-${i}`, // e.g. "abc123-0"
vector: chunk.embedding,
metadata: {
resourceId,
content: chunk.content,
},
}))
await index.upsert(toUpsert)
}
// Query
export async function findRelevantContent(query: string, k = 4) {
const userEmbedding = await generateEmbedding(query)
const result = await index.query({
vector: userEmbedding,
topK: k,
includeMetadata: true,
})
return result
}
text-embedding-ada-002 generates embeddings with 1536 dimensions, so the index we created must have 1536 dimensions.
Create Resource Server Action
We will create a server action to create a new resource and upsert it to the index. This will be used by our chatbot to store information.
'use server'
import { z } from 'zod'
import { upsertEmbeddings } from '@/lib/ai/upstashVector'
// A simple schema for incoming resource content
const NewResourceSchema = z.object({
content: z.string().min(1),
})
// Server action to parse the input and upsert to the index
export async function createResource(input: { content: string }) {
const { content } = NewResourceSchema.parse(input)
// Generate a random ID
const resourceId = crypto.randomUUID()
// Upsert the chunks/embeddings to Upstash Vector
await upsertEmbeddings(resourceId, content)
return `Resource ${resourceId} created and embedded.`
}
Chat API route
This route will act as the “backend” for our chatbot. The Vercel AI SDK’s useChat hook will, by default, POST to /api/chat with the conversation state. We’ll define that route and specify the AI model, system instructions, and any tools we’d like the model to use.
import { openai } from '@ai-sdk/openai'
import { streamText, tool } from 'ai'
import { z } from 'zod'
// Tools
import { createResource } from '@/lib/actions/resources'
import { findRelevantContent } from '@/lib/ai/upstashVector'
// Allow streaming responses up to 30 seconds
export const maxDuration = 30
export async function POST(req: Request) {
const { messages } = await req.json()
const result = streamText({
// 1. Choose your AI model
model: openai('gpt-4o'),
// 2. Pass along the conversation messages from the user
messages,
// 3. Prompt the model
system: `You are a helpful RAG assistant.
You have the ability to add and retrieve content from your knowledge base.
Only respond to the user with information found in your knowledge base.
If no relevant information is found, respond with: "Sorry, I don't know."`,
// 4. Provide your "tools": resource creation & retrieving content
tools: {
addResource: tool({
description: `Add new content to the knowledge base.`,
parameters: z.object({
content: z.string().describe('The content to embed and store'),
}),
execute: async ({ content }) => {
const msg = await createResource({ content })
return msg
},
}),
getInformation: tool({
description: `Retrieve relevant knowledge from your knowledge base to answer user queries.`,
parameters: z.object({
question: z.string().describe('The question to search for'),
}),
execute: async ({ question }) => {
const hits = await findRelevantContent(question)
// Return array of metadata for each chunk
// e.g. [{ id, score, metadata: { resourceId, content }}, ... ]
return hits
},
}),
},
})
// 5. Return the streaming response
return result.toDataStreamResponse()
}
Chat UI
Finally, we will implement our chat UI on the home page. We will use the Vercel AI SDK’s useChat hook to render the chat UI. By default, the Vercel AI SDK will POST to /api/chat on submit.
'use client'
import { useChat } from 'ai/react'
export default function Home() {
// This hook handles message state + streaming from /api/chat
const { messages, input, handleInputChange, handleSubmit } = useChat({
// You can enable multi-step calls if you want the model to call multiple tools in one session
maxSteps: 3,
})
return (
<div className="mx-auto max-w-md py-6">
<h1 className="text-xl font-bold mb-4">RAG Chatbot with Upstash Vector</h1>
{/* Render messages */}
<div className="space-y-2 mb-8">
{messages.map(m => (
<div key={m.id} className="border p-2 rounded">
<strong>{m.role}:</strong>
<div>
{/* If the model calls a tool, show which tool it called */}
{m.content.length > 0 ? (
m.content
) : (
<i>calling tool: {m?.toolInvocations?.[0]?.toolName}</i>
)}
</div>
</div>
))}
</div>
{/* Text input */}
<form onSubmit={handleSubmit} className="flex gap-2">
<input
className="flex-1 border rounded px-2 py-1"
placeholder="Say something..."
value={input}
onChange={handleInputChange}
/>
<button className="px-4 py-1 bg-black text-white rounded" type="submit">
Send
</button>
</form>
</div>
)
}
Run the Chatbot
Now, we can run our chatbot with the following command:
Here is a screenshot of the chatbot in action:
If you would like to see the entire code of a slightly revised version of this chatbot, you can check out the GitHub repository. In this version, the user chooses which embedding model to use through the UI.
Conclusion
Congratulations! You have successfully created a RAG chatbot that uses Upstash Vector to store and retrieve information. To learn more about Upstash Vector, please visit the Upstash Vector documentation.
To learn more about the AI SDK, visit the Vercel AI SDK documentation. While creating this tutorial, we used the RAG Chatbot guide created by Vercel, which uses PostgreSQL with pgvector as a vector database. Make sure to check it out if you want to learn how to create a RAG chatbot using pgvector.